p-value의 정의
귀무가설이 참이라는 가정 하에, 계산된 검정 통계량이 귀무가설을 얼마나 지지하는지 나타내는 확률
(p-value가 작음 → 귀무가설이 참일 확률이 적어짐)
확률이기에 0~1로 표준화된 지표
p-value가 작으면 귀무가설이 참일 확률이 적어진다. 하지만 얼마나 작아야 '통계적'으로 작다고 할 수 있을까?
- 통상적으로 0.05(혹은 0.01)보다 작으면 귀무가설이 참일 확률이 매우 작다고 판단한다.
- 검정통계량 : 귀무가설이 참이라는 가정 아래 얻은 통계량
- 귀무가설(H0)이 참일 때, 관측된 결과 또는 더 극단적인 결과를 얻을 확률
- 귀무가설이 옳다는 가정하에, 검정통계량이 이론적으로 따르는 표집분포상에서 표본에 기반한 검정통계량보다 더 극단적인 확률을 말한다.
- 표본에 기반한 검정통계량보다 더 극단적인 확률이 매우 작다면? 귀무가설을 기각
- 귀무가설(null hypothesis, H0)이 맞다는 전제 하에, 통계값(statistics)이 실제로 관측된 값 이상일 확률을 말한다.
- 통계량 : 분포로부터 계산되는 값을 말하는데, 흔히 평균, 또는 평균의 차이, 분산, nth moment 등이 될 수 있음.
이렇게 냅다 정의만 써놓자니 무슨 소리인지 잘 이해가 가지 않는데, 차근차근 살펴보며 이해해보자.
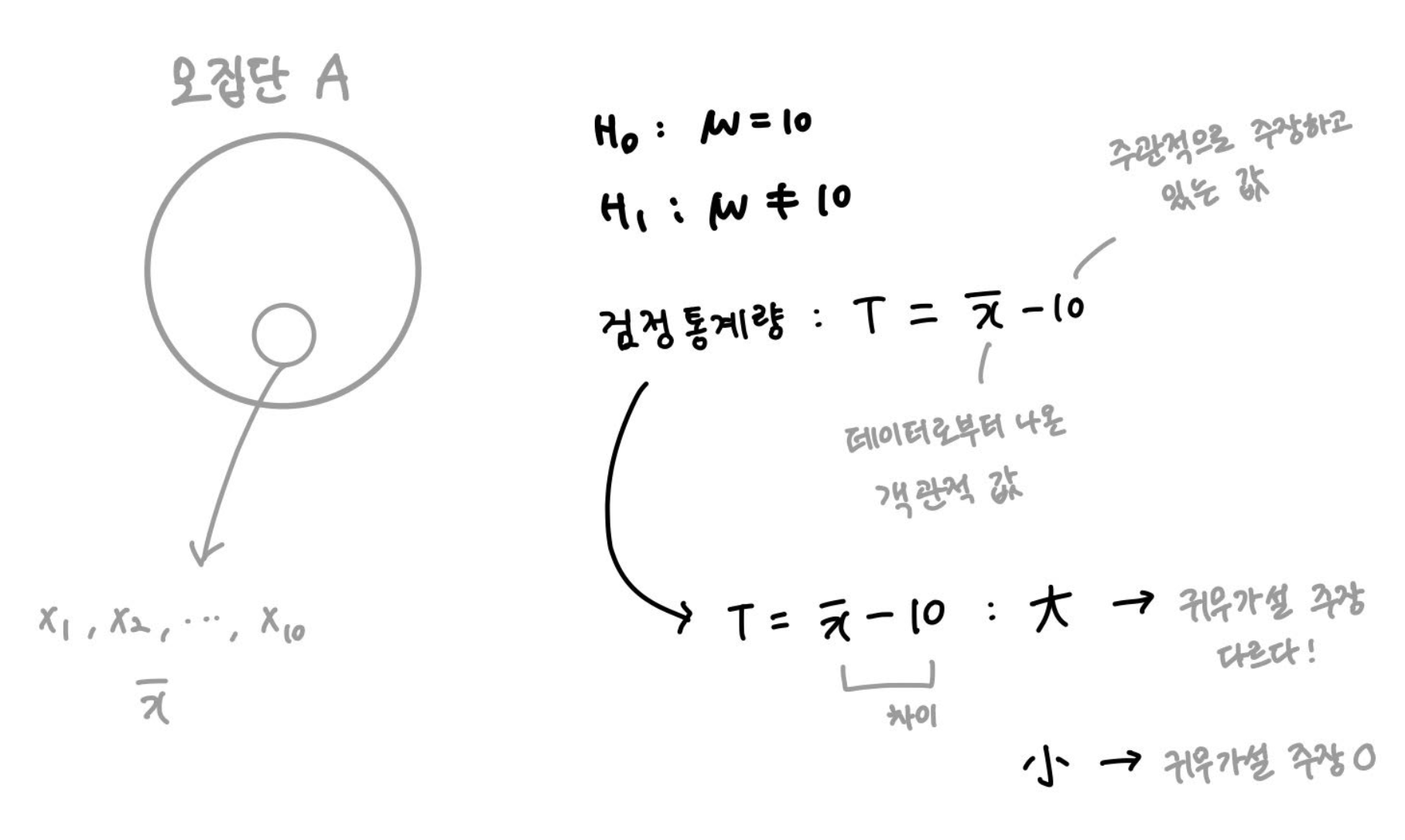
모집단 A의 평균이 10일 거라는 가설을 검증하고 싶다. 모집단 A로부터 추출한 샘플들이 있고, 샘플을 통해 얻은 객관적 값인 $\bar{x}$가 있다고 하자. 검정통계량의 경우 객관적 값과 가설에서 설정한 주관적 값의 차이가 된다. (여기서 분자에 주목하라. 분모는 차치하고.) 차이가 클수록 모평균이 10이라는 귀무가설의 주장과는 멀어지게 될 것이다. 하지만 차이가 얼마나 크고, 얼마나 작아야 귀무가설을 기각할 수 있을까? 여기에 사용되는 개념이 바로 p-value이다.
예시



(위 내용과 비슷한 내용이지만, 약간 다른 접근법이 있어서 정리해봄)
* 가설검정 :
모집단의 특징에 대한 통계적 가설을 ‘추출된 표본’을 통하여 검토하는 추론 방법

- 모집단의 특징에 대한 통계적 가설을 검증하기 위해, 표본을 추출해서 검토하는 것이 '가설 검정'이다.
현실에서 모집단에 대한 실제 정보를 알고있긴 힘들다. 예를 들어 우리나라 50대 남자의 평균 키를 알고 싶다고 할 때, 한명도 빠짐없이 모든 사람을 검사하기엔 비용과 시간 측면에서 현실적으로 어렵지 않은가?
- 이 예시에서도 전체 10,000개를 다 검사할 수 없으니 100개만 선택해서 검사한다고 해보자.
100개를 추출해서 구한 평균이 모평균과 유사할까? 그렇다고 말할 수 없다.
왜냐하면, 내가 100개를 고를 때 위처럼 분포의 양극단 같은 곳에 있는 것들이 선택될 수도 있기 때문이다.
이처럼, 100개를 선택했을 때 그 100개의 평균이 모분포의 평균에 근접한 것이 골라졌다고 말할 수 없는 경우가 얼마든지 발생할 수 있다. 이에, 'sampling된 데이터의 평균은 모분포의 평균과 얼마나 유사할 것인가?'라는 질문이 생길 수 있다.
정리를 해보자
- 가설검정이라는 것은 전체 데이터의 일부만을 추출하여 평균을 내고, 그 평균이 전체 데이터의 평균을 잘 반영한다는 가정 하에 전체 데이터의 평균을 구하는 작업이다.
- 하지만 아무리 무작위 추출을 잘 한다 하더라도, 추출된 데이터의 평균은 전체 데이터의 평균에서 멀어질 수 있는 경우가 발생한다.
- 따라서 내가 추출한 이 데이터의 평균이 원래의 전체 데이터의 평균과 얼마나 다른 값인지를 알 수 있는 방법이 필요하게 되는데 여기에 사용되는 값이 p-value라고 할 수 있다.
- 우리는 평균이 100이라는 가정(귀무가설)하에서는 sampling된 데이터의 평균이 100 근처에 있을 것이라는 생각을 하게 된다. 또한 이는 sampling된 데이터의 평균이 100에서 멀면 멀수록, 모분포의 평균이 100이 아닐지도 모른다는 생각을 하게 된다는 것을 의미한다.
모분포의 평균이 100이다"라는 귀무가설이 참이라는 가정 하에,
100개의 데이터를 sampling 할 때 이론적으로 나올 수 있는 평균의 분포에서
지금 내가 갖고 있는 값인 95 보다 큰 값이 나올 수 있는 확률. 이것이 p-value 이다.
위의 예에서 본 것과 같이, 만약 그럴 확률이 매우 낮다면 우리는 귀무가설을 기각할 수 있게 된다.
우리는 통계적으로 일어나기 매우 어려운 일이 일어났을 때,
(우연히 발생할 가능성이 매우 희박한 사건이 실제로 발생했을 때)
아마도 우연히 일어났다기 보다는 다른 이유 때문에 일어났다고 생각한다.
p-value 역시 그와 같은 경향을 따른다.
예시 1) 매우 어려운 시험에서 우연히 100점을 받을 확률은 매우 낮은데, 정말로 100점을 받은 사람이 있다고 하자. 우리는 그가 우연히 100점을 받았다고 생각하기보다, 우연히 100점을 받은 것은 아니라고 생각한다.
예시 2) 또한 로또를 연속 5번 맞춘 사람이 있다면, 우연히 그런 일이 일어날 가능성은 매우 작으므로 그 일은 우연이 아니라고 생각하고 뭔가 모종의 음모가 있다고 의심해 보게 된다.

50개의 데이터를 추출했고 그 평균이 95이다. 아마도 이 데이터가 평균이 100이고 분산이 30인 모분포 P에서 왔을 것 같다.
평균이 100 이고 분산이 30인 모분포에서 50 개를 추출할 때 그 50개의 평균이 95가 나올 확률(A)이 0.001이라면?
- 즉, 평균이 100, 분산이 30인 모분포에서 50개를 선택했을 때 평균이 95가 나오는 경우가 매우 드물다면, 아마도 내가 갖고 있는 데이터는 모분포 P에서 왔다고 말하기 조금 꺼려진다.
- 아마도 이렇게 확률이 적은 일이 지금 실제로 일어났다고 생각하기 보다는 애초에 가졌던 가설, 즉, 데이터 50개를 추출한 모분포가 평균이 100 이고 분산이 30 이다, 이 가설이 아닐 것이라고 생각한다는 것이다.
반대로 그럴 확률(A)이 0.65 라면, 그렇다면 이런 경우는 그리 어려운 일이 아니므로 그럴듯 하다.

- 위 그림에서 보면, 실제로 가능한 m(평균)의 분포가 위와 같을 때 내가 구한 평균이 m2라면 p-value가 매우 작다.
- 이럴 경우, 그렇게 희박한 일이 실제로 일어났다고 하기 보다는 저 이론적 분포를 가져온 가설(귀무가설)이 잘못되었다고 생각한다.
- 반대로 m1과 같이 귀무가설 하에선 별스럽지 않은 일이라면 아마도 귀무가설이 맞을 것이다.
유의수준(α, alpha)과의 관계
- 유의수준은 가설 검정에서 연구자자가 결정하는 임계값(threshold)이다.
- 귀무가설이 옳다는 가정하에서 관찰값이 얼마나 드물게 일어나야 영가설을 기각할 정도인지를 결정하는 확률
- 보통 0.05 또는 0.01과 같은 작은 값을 사용하며, 연구자가 결과를 평가하는 데 얼마나 엄격하게 판단할 것인지를 나타낸다.
- 연구자가 최대로 허용할 수 있는 오류의 임계값
- 예를 들어, 유의수준을 0.05로 설정하면 실험 결과가 5% 이하의 확률로 발생할 때 귀무가설을 기각한다.
- 가설 검정에서는 계산된 p-value와 미리 설정한 유의수준을 비교한다.
- p-value < 유의수준이면, 귀무가설을 기각하고 대립가설을 받아들인다.
스스로 해보는 개념 정리
- p-value란 귀무가설이 옳다는 가정 하에, 계산된 검정 통계량이 귀무가설을 얼마나 지지하는지를 나타내는 확률을 말한다. 따라서 p-value가 작으면 귀무가설이 참일 확률이 적어진다고 할 수 있다. 통상적으로 0.05 혹은 0.01보다 작으면 귀무가설을 기각하게 된다.
- 또한 p-value는 모집단에서 구한 평균과, sampling하여 구한 평균이 서로 얼마나 다른 값인지를 알 수 있는 방법이라고 할 수 있다. 모평균이 100이고 샘플링해서 얻은 값이 95라고 할 때, 95 이상의 값을 가질 확률이 0에 가깝다면 모평균이 100이라는 귀무가설을 기각하게 된다. 따라서 p-value값이 매우 작다면, 귀무가설을 기각하게 된다.
⬇️ Reference ⬇️
https://www.youtube.com/watch?v=tpow70KGTYY&t=2s (정말 명강의입니다..!)
https://adnoctum.tistory.com/332#footnote_332_1
개인적으로 공부하며 요약한 자료입니다.
오류 발견 시 댓글 남겨주시면 정정하겠습니다!
'📊 Statistics' 카테고리의 다른 글
| [통계/Python] 이표본 비율 검정, ADP 실기 29회 풀이 (0) | 2023.08.26 |
|---|---|
| [통계/Python] ANOVA & 사후검정, ADP 실기 29회 풀이 (0) | 2023.08.19 |
| [통계/Python] 맥니마 검정(McNemar's test) 개념 및 예제, ADP 실기 28회 풀이 (0) | 2023.08.15 |
| [통계/Python] 음이항분포(Negative Binomial Distribution) 개념 및 예제 (0) | 2023.08.12 |
| [통계/Python] 다항분포(Multinomial Distribution) 개념 및 예제 (0) | 2023.08.08 |