[ 맥니마 검정(McNemar's test) ]
목적 : 2개의 대응 표본을 가지고 범주형 변수의 분포가 변화했는지 검정
- 짝지은(paired) 범주형 데이터의 2x2 분할표가 있을 때, Column과 Row의 주변확률(marginal probability)가 같은지 검정
- paied, 연관 : 동일인에 대해 두 번 측정하거나, 부모-자식처럼 관련있는 사람들에 대해 측정
- 즉, 범주형 변수가 2개일 때 쓸 수 있는 방법
- 맥네마 검정은 분할표에서 각 관측치 간에 독립성이 만족하지 않을 때 사용하는 검정
- 독립성 : 두 변수가 서로 영향을 주지 않는 상황. 두 변수 간에 아무런 상관관계가 없다는 뜻
- 머신러닝에서는 2x2 혼동행렬에 대한 예측모델의 정확도를 비교하는 방법으로도 사용

가설

검정통계량

검정 통계량은 카이제곱 분포를 따르므로, 이 값을 자유도가 1인 카이제곱 분포의 분포표를 사용하여 p-value를 계산할 수 있음
Example 1
80명을 모집해 프로모션 이벤트를 열고, 이벤트 전후로 상품에 흥미가 있는지를 설문조사하여 얻은 결과가 다음과 같다. 흥미를 갖다가 사라진 사람보다 흥미를 갖지않다가 갖게 된 사람이 더 많았다. 이것이 우연인지 이벤트의 효과인지를 유의수준 0.05로 검정하라.
- H0 : 흥미가 없다가 있게 된 경우와 있다가 없게된 경우는 동일한 확률로 배분된다.
- H1 : 흥미가 없다가 있게 된 경우와 있다가 없게된 경우는 동일한 확률로 배분되지 않는다.
출처 : 핵심만 요약한 통계와 머신러닝 파이썬 코드북 171p
import pandas as pd
table = pd.DataFrame([[9,12], [24,35]], index=["전_있음", "전_없음"] , columns=["후_있음", "후_없음"])
print(f"[데이터 확인]\n{table}\n")
# 라이브러리 검정
from statsmodels.stats.contingency_tables import mcnemar
# correction=False는 연속성 보정 허용 X
# exact가 True -> 이항분포, False -> 카이제곱분포 사용
mc = mcnemar(table.values, exact=False, correction=False)
print("McNemar's Chi-squared test")
print("검정통계량 {:3f}, p-value {:3f}\n".format(mc.statistic, mc.pvalue))
Example 2 : ADP 실기 28회
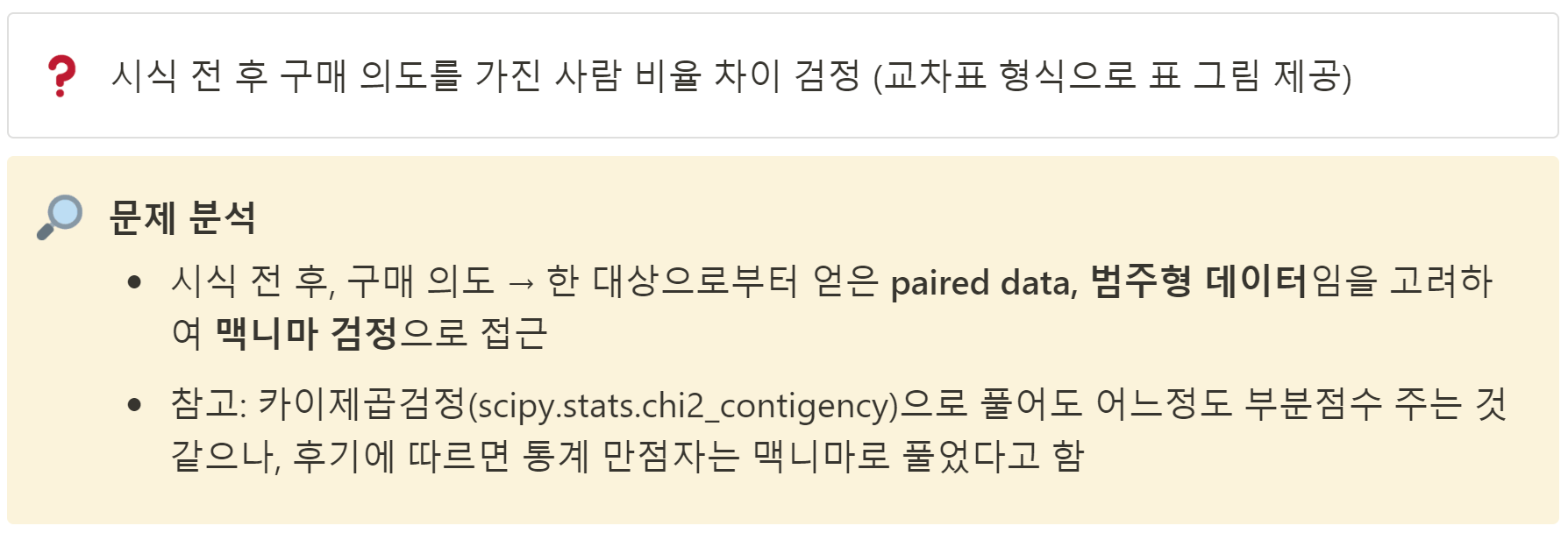
5-1) 시식여부가 구매의사에 영향을 주는지 가설을 설정하시오(5점)
- 귀무가설 : 시식 전후의 구매의사는 같다. (즉, 시식 여부가 구매의사에 영향을 미치지 않는다.)
- 대립가설 : 시식 전후의 구매의사는 다르다. (즉, 시식 여부가 구매의사에 영향을 미친다.)
(데이터 출처는 데이터 마님 사이트입니다.)
5-2) 검정하고 결과를 분석하시오(5점)
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/Datamanim/datarepo/main/adp/28/p5_.csv')
df.head()
데이터를 불러오면 위와 같은 형태이다.
시식 전, 후 의사유무에 따라 빈도표를 생성해주기 위해 데이터 전처리를 진행한다.
# "시식 전"과 "시식 후" 각각 유무에 따른 빈도 계산
before_count = len(df[df['data'].str.contains('시식전_유')])
after_count = len(df[df['data'].str.contains('시식후_유')])
no_before_count = len(df) - before_count
no_after_count = len(df) - after_count
# 빈도표 생성
table = pd.DataFrame([[before_count, no_before_count], [after_count, no_after_count]],
index=["시식 전 있음", "시식 후 있음"],
columns=["시식 전 없음", "시식 후 없음"])
print(f"[데이터 확인]\n{table}\n")

# 라이브러리 검정
from statsmodels.stats.contingency_tables import mcnemar
mc = mcnemar(table.values, exact=False, correction=False)
print("McNemar's Chi-squared test")
print("검정통계량 {:3f}, p-value {:3f}\n".format(mc.statistic, mc.pvalue))

가설 검정 결과, p-value은 0.185로 유의수준 0.05보다 크다.
따라서 유의수준 0.05 하에서 귀무가설을 기각할 수 없으며 시식 전후의 구매의사는 같다고 할 수 있다.
참고 : 맥니마 검정 vs. 카이제곱 검정 vs. 대응표본 t 검정

⬇️ Reference는 더보기에 ⬇️
728x90
'📊 Statistics' 카테고리의 다른 글
| [통계/Python] 이표본 비율 검정, ADP 실기 29회 풀이 (0) | 2023.08.26 |
|---|---|
| [통계/Python] ANOVA & 사후검정, ADP 실기 29회 풀이 (0) | 2023.08.19 |
| [통계/Python] 음이항분포(Negative Binomial Distribution) 개념 및 예제 (0) | 2023.08.12 |
| [통계/Python] 다항분포(Multinomial Distribution) 개념 및 예제 (0) | 2023.08.08 |
| [통계/R] 베이지안 회귀 기초 개념 & ADP 실기 26회 R 구현 (0) | 2023.08.05 |