⬇️ 더 많은 자료와 코드는 깃허브에서 볼 수 있습니다 ! ⬇️
이표본 모비율 검정은 두 비율이 같은지, 차이가 있는지를 보는 방법이다.
개념과 예시를 통해 자세히 알아보자.
예시
- 1) 금년도 대통령 선거에서 특정후보에 대한 지지율에 유권자의 성별에 따른 차이가 있는가?
- 2) 어느 공장에서 제품을 만들어 내는 두 대의 기계가 있는데 두 기계의 불량률이 서로 다른가?
신뢰구간

검정통계량
1) 표본비율을 이용한 검정통계량
- 신뢰구간에 사용되는 방법과 같음
- 표본비율을 이용한 검정통계량, 공통비율을 이용한 검정통계량 간에 큰 차이가 있는 것은 아니지만, 귀무가설이 틀릴 가능성이 많을 때는 이 표본비율을 사용하는 방법이 더 유익하다고 함
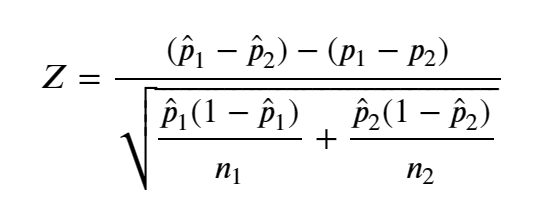
2) 가중평균(공통비율)을 이용한 검정통계량 ⭐
- 주의 : 신뢰구간에서 사용하는 공식과 다르다.
- 일반적으로 통용되는 방법
- 이러한 두 모집단의 모비율($p_1,p_2$)비교는, 모평균과 유사하게 두 모비율의 차($p_1 - p_2$)를 검정함으로써 가능
- 두 모집단에서 서로 독립적으로 추출한 표본비율의 차($\hat p_1 - \hat p_2$)는 표본의 크기가 충분히 클 때 평균이 $p_1 - p_2$, 분산이 $\cfrac{p_1 (1-p_1 )}{n_1} + \cfrac{p_2 (1-p_2 )}{n_2}$인 정규분포를 따른다.
- 여기서 분산의 추정을 위해서는 $p_1, p_2$를 모르므로 두 표본비율($\hat p_1 , \hat p_2$)에 대해 표본의 크기를 가중값으로 취한 가중평균 $\overline p$를 사용한다.
합동표본비율(공통비율, 가중평균)
- $n_1 {\hat p}_1 = x_1$ 만 남음 (분모 소거)

가설검정 형태

Example 1 : ADP 실기 29회
C사 생산 제품 1000개 중 양품이 600개, D사 생산 제품 500개 중 양품이 200개 이다. 두 회사의 양품률에 차이가 있는지 검정하여라.
- 귀무가설 : 두 집단 간의 모비율 차이가 없다.
- 대립가설 : 두 집단 간의 모비율 차이가 있다.
import numpy as np
n1 = 1000
p1 = 600/1000
n2 = 500
p2 = 200/500
conf_0 = 0.05
from scipy.stats import norm
d = p1 - p2
conf_z = norm.ppf(1 - conf_0/2) # twoway이므로 /2
se = np.sqrt(p1*(1-p1)/n1 + p2*(1-p2)/n2)
me = conf_z * se
pe = (n1*p1+n2*p2)/(n1+n2) # Pooled estimate
se2 = np.sqrt((pe * (1 - pe))/n1 + (pe * (1 - pe)) / n2)
zstat = d / se2
conf_z = norm.ppf(1-conf_0/2)
me2 = conf_z * se2
sp = 1 - norm.cdf(np.abs(zstat))
cv = norm.ppf(1-conf_0/2)
cv ='+/-{:.3f}'.format(cv)
print('[검정]')
print('임계값 : {}, 검정통계량 : {:.3f}'.format(cv, zstat))
print('유의수준 : {}, 유의확률 : {:.3f}'.format(conf_0, sp))

- 검정통계량이 임계값보다 크므로 기각역에 속해 귀무가설을 기각한다.
- 따라서 두 회사의 양품률에 차이가 있다고 할 수 있다.
728x90
'📊 Statistics' 카테고리의 다른 글
| [통계/개념] p-value란 대체 무엇인가? (+ 유의수준) (0) | 2023.09.16 |
|---|---|
| [통계/Python] ANOVA & 사후검정, ADP 실기 29회 풀이 (0) | 2023.08.19 |
| [통계/Python] 맥니마 검정(McNemar's test) 개념 및 예제, ADP 실기 28회 풀이 (0) | 2023.08.15 |
| [통계/Python] 음이항분포(Negative Binomial Distribution) 개념 및 예제 (0) | 2023.08.12 |
| [통계/Python] 다항분포(Multinomial Distribution) 개념 및 예제 (0) | 2023.08.08 |