3강에서는 손실함수란 무엇이고 어떤 종류가 있는지,
최적화는 무엇이고 왜 사용하는지 등에 대해서 학습한다.
(2017년 강의 기준)
[ Loss Functions (손실함수) ]
- 손실함수란 최적의 weight를 구하기 위해, 현재의 weight가 좋은지 나쁜지 정량화하는 방법에 사용되는 함수이다.
- 머신러닝과 딥러닝에서 모델 예측값과 실제 타깃 값의 차이를 측정하는 함수로, 모델이 얼마나 잘 예측하고 있는지를 평가하고 모델의 매개변수를 조정하는 데 사용된다.
- 만약 예측값과 실제값의 차이가 크다면 손실함수 값이 크고, 모델 예측 성능이 낮다고 할 수 있다.
- 따라서, 손실 함수의 값을 최소화하여 모델의 성능을 향상시키는 것이 목표이다.

고양이, 자동차, 개구리 3가지 클래스를 비교하는 경우를 예로 들어보며 이해해보자.
- $x_i : image$
- $y_i:integer \; label$ (고양이 : 0, 자동차 : 1, 개구리 : 2 등)
Multiclass SVM Loss (Hinge Loss)
- 이미지 분류에 적합한 손실함수 중 하나인 Multiclass SVM Loss
- Hinge Loss : SVM 알고리즘을 위한 손실함수
- 최소값은 0, 최대값은 무한대

위의 고양이, 자동차, 개구리 분류 예제에서 SVM Loss를 계산하는 과정은 아래 슬라이드와 같다.



- 최종 Loss값은 세 클래스 Loss의 평균이 된다.
- 이 예시에서 얻은 최종 Loss 값 5.27은 분류기가 5.27만큼 train data를 틀리게 분류하고 있다는 ‘정량적 지표’이다.
Example Code
def L_i_vectorized(x,y, W):
scores = W.dot(x)
margins = np.maximum(0, socres - scores[y] + 1)
margins[y] = 0
loss_i = n.sum(margins)
return loss_i- margins[y] = 0는 정답 클래스에 대한 손실을 0으로 설정하는 코드하여 전체를 순회하지 않게 해주는 코드이다.
Related Questions
1️⃣ 자동차 score를 약간 변경시키면 어떤 변화가 있을까?

- 자동차의 score가 4.9에서 1을 뺀 3.9라고 하더라도, loss는 0이다.
- cat과 frog에 각각 score +1을 해도, 자동차의 score가 여전히 더 높기 때문에 loss는 0이다.
→ 여기서 SVM Hinge Loss의 특징을 발견할 수 있다. score 자체의 값 보다는 정답 클래스 & 정답이 아닌 클래스 간 score 비교에 초점을 준다는 것이다.
SVM Hinge Loss 특징
데이터에 민감하지 않다. 둔감하다.
score 자체가 몇 점인지보다는 ‘정답 클래스가 다른 클래스보다 높은가’에 초점을 둔다.
2️⃣ W의 초기값을 0만큼 아주 작게 초기화 시킨다면, Loss는 어떻게 될까?

- W 행렬들의 값을 0이라고 가정하면 각 클래스의 Loss는 max(0, 0-0+1) + max(0, 0-0+1)=2
- 즉 Loss 식의 $s$에 0을 대입하면, max값은 항상 1이 되어 1+1 = 2가 도출된다.
- Loss는 각각 2, 2, 2가 되어 최종 Loss 또한 2가 된다.
- 위의 예제는 Class가 3개의 경우이고, 각 클래스 당 2번씩 순회하여 1+1=2가 도출된다고 볼 수 있다.
- 만약 Class가 10개인 경우 Loss는 10-1=9가 된다.
- 위를 일반화 시킨다면 $Loss= class \; number-1$
- 이 경우는 디버그용으로 많이 사용되며 최초 학습 시 Loss값이 규칙에 맞는지, 학습이 제대로 되는지를 알 수 있다. 이를 sanity check라고 한다.
3️⃣ 정답 클래스 $(j=y_i)$경우를 포함한다면?

- 고양이의 Loss를 예로 든다면 $max(0, 3.2-3.2+1)=1$이 추가되어, 최종 Loss는 3.9가 된다.
- 모든 클래스의 Loss는 각 1이 추가되고 이에 따라 최종 Loss도 1이 증가한다.
4️⃣ Loss가 0이 되게 하는 Weight parameter를 발견했다고 가정하자. 만약 이 Weight parameter는 유일한가? ⭐


- Weight의 2배도 역시 Loss가 0이 되는 걸 확인할 수 있다. 따라서 W는 유니크하지 않다.
- train data에서 맞았던 weight가 test에서는 맞지 않을 수 있는 문제가 발생할 수 있다.
- 따라서 test data에도 맞을 수 있는 weight를 찾아내야한다. 이를 위해 사용하는 것이 규제이다.

- 왼쪽의 파란색 선은 train data를 통해 얻은 것이고, 초록색은 test data이다.
- test data에 대해 예측하지 못하므로 Overfitting(과적합)의 우려가 있다.
- train data에만 맞는 weight 말고, test data에도 맞는 weight를 찾아내자는 것이 규제의 목적 !
[ Regularization (규제) ]
- 다양한 W중 Loss가 0인 것을 선택하는 것은 모순이다. 이는 오직 train data loss에만 신경쓰며 train data에만 꼭 맞는 W를 찾으라고 말하는 것과 같기 때문이다.
- 머신러닝의 핵심은 train data를 이용해서 찾은 어떤 분류기를 test data에 적용하는 것이다.
- 따라서 train data에 대한 성능에 관심있는 것이 아니라, test 데이터에 적용했을 때의 성능에 관심이 있는 것이다.


- data loss term (train data 입장) vs. regularization term (test data 입장)
- train data가 자신에게만 맞는 것을 학습하려고 할 때, regularization은 ‘그렇게 하면 이 정도의 패널티는 감안해야해’하며 서로 싸우면서 최적의 weight를 찾아나가는 것

- 일반적으로 쓰이는 규제 방법은 위와 같다.
- 관련 규제 방법은 추후 포스팅 예정
[ Softmax (Cross-Entropy) ]
- Multinomial Logistic Regression
- Hinge Loss와는 다르게 score 자체에 의미를 부여하는 것이 특징이다.
- 모든 score에 exp를 취하여 다 더한 후, 원하는 클래스의 점수를 exp 취해 나눠 확률 값을 구한다.
- Softmax Loss의 최솟값은 0, 최대값은 무한대

빨간 박스를 모두 더하면 188.68 → 고양이의 확률은 24.5 / 188.68 = 0.13, 마지막으로 이 값에 -log를 취한다.

- Hinge Loss : max를 취해서 값을 구함
- Cross-Entropy Loss : exp를 취해 확률 값을 구함
- 위에서 Hinge Loss는 데이터에 둔감한 편이었지만, Cross-Entropy Loss는 데이터가 조금만 달라져도 확률이기 때문에 영향을 쉽게 받는다.
[ Optimization (최적화) ]
- 산속에서 평지(즉, loss=0)를 찾아 골짜기를 내려가는 과정과 유사하다.
- 손실함수를 통해 weight를 좋은지, 안좋은지 정량화하여 평가하였으니 좋은 weight 값을 찾아야한다. 이럴 때 쓰는 방법이 최적화이다.
- 최적화란 모델의 손실 함수(Loss Function)를 최소화하거나 목표 지표를 최대화하는 방향으로 모델의 파라미터를 조정하는 과정을 의미한다.
- 딥러닝 모델은 입력 데이터로부터 출력을 예측하고, 이때 모델의 파라미터들이 사용되는데, 이 파라미터들을 조정하여 원하는 결과를 얻기 위해 최적화를 사용한다.
1. Random Search (임의탐색)
- Random Search(임의 탐색)는 산 속에서 눈을 가리고 밑바닥을 내려가는 것처럼 매우 비효율적이므로 사용하지 않는게 좋다.
- 가장 높은 성능 수치가 95%이고, 낮은 수치가 15.5% → 차이가 굉장히 심함

2. Gradient Descent (경사하강법)
- 산의 기하학적 특성, 기울기를 통해 어느 방향으로 내려가야하는 지 탐색하는 방법
2-1. numerical gradient (수치적 방법)
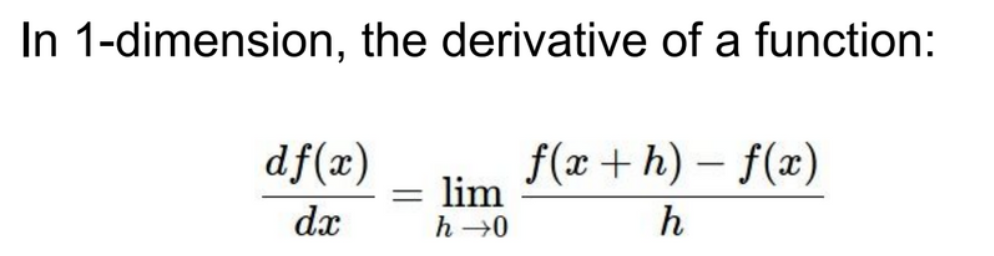
- 1차원의 경우 왼쪽과 같은 미분식으로 경사(slope)를 구한다.
- 다차원이라면 편미분된 벡터의 값으로 나온다.

- 수치적 방법을 통해 경사를 구하는 구체적 예시이다.
- W과 Loss가 있을 때, 위처럼 한 차원씩 미분을 통해 경사를 구한다.
- 이렇게 하면 CNN 모델 같은 경우 수천만개의 W가 있을 수 있는데 계산이 너무 느려 비효율적이다.
2-2. analytic gradient (해석적 방법)
- 뉴턴과 라이프니츠가 만들어 놓은 미분을 이용하면 효율적인 계산 가능
- 추후 chain rule과 관련

- 수치적 방법은 근사적이고 느리지만 간편, 해석적 방법은 정확하고 빠르지만 에러 가능성이 존재
- 따라서 해석적 방법을 주로 사용하고, 디버깅 및 점검 시에는 수치적 방법을 활용하는 것이 좋다. 이를 gradient check라고 한다.

- 양의 기울기가 기울기가 0인 지점으로 가려면 음의 방향으로 가야하기 때문에, -를 붙여줘야함
- step_size는 learning rate로, 적절한 값 찾는 것이 중요
Stochastic Gradient Descent (SGD)

- data set의 Loss 계산은 수백만번의 계산이 필요할 수 있는데, 이렇게 심층 신경망 등의 큰 모델을 학습할 때 주로 사용되며, 미니 배치 경사 하강법(Mini-Batch Gradient Descent)라고도 불림
- 전체 data set의 gradient와 loss를 계산하기 보다는, minibatch라는 작은 train sample set으로 나눠서 학습하는 것
- minibatch를 두어서 데이터 개수를 잘라서 사용
- 보통 2의 승수로 사용
- 256이라면, 256개를 가지고 W를 업데이트하고 또 그다음 256개를 가지고 W를 업데이트하는 방식
- cpu gpu 메모리 환경 사양에 따라 조정
초기 이미지 분류 방법

- 원래는 위처럼 feature를 뽑아내고 이를 합쳐서, linear regression에 던져주는 형태

- 전통방식은 이미지를 직접 사람이 인식하여 bin, frequency를 추출하여 사용하는 흐름이었음
- 하지만 지금은, 입력된 이미지에서 스스로 특징을 뽑아내도록 사용 (CNN)
- 원래는 위처럼 feature를 뽑아내고 이를 합쳐서, linear regression에 던져주는 형태
추후 파이썬으로 구현하면서 이론을 복습해도 좋을 것 같다.
완전한 내 지식이 되는 그날까지 화이팅
⬇️ Reference는 여기에 ⬇️
개인적으로 공부하며 요약한 자료입니다.
오류 발견 시 댓글 남겨주시면 정정하겠습니다!
728x90